Designing Single Table Access Patterns

System Design Methods
What is Single Table Access?
In this article, we'll take a closer look into designing access patterns using the single table strategy. This has been a pretty hot topic in the industry over the last few years because it positions your application to use NoSQL tables in a way that promotes cost-effective savings and fast read/write access. By identifying your access patterns, you will equip your application to perform at great speed and produce meaningful results with minimal overhead. Unlike traditional relational databases (RDBMS) systems, NoSQL tables are key-value databases built for performing extremely high volumes of transactions. They do not support relational queries. This means you won't find SQL JOINS when accessing a NoSQL Table. Joins are not typically supported because they come at an expensive cost. A trade-off comes with using NoSQL vs SQL table. Some popular choices of NoSQL tables are MongoDB and DynamoDB.
DynamoDB
Amazon DynamoDB is a fully managed proprietary NoSQL database service that supports key-value and document data structures and is offered by Amazon.com as part of the Amazon Web Services portfolio. DynamoDB exposes a similar data model to and derives its name from Dynamo, but has a different underlying implementation. It is used in Financial Services, Marketing and Advertising, Retail, Higher Education, Hospital and Health, Telecom among other industries.
Normalized Data VS Denormalized Data
SQL Normalization:
One of the biggest mental transitions from RDBMS to NoSQL is normalization. Typically, with relational databases, we want to have a high degree of normalization. This means that we want to avoid duplicate data being present in any record, table or row. We also want to ensure our relational integrity using the concept of foreign keys and constraints. Using this ensures that our data state is accurate and avoids stale and orphaned records. Orphaned Records are those that do not have any parent or sibling relationship or are thus lost.
NoSQL Denormalization:
As mentioned before, using NoSQL comes with a trade off. We trade-off normalized data with speed to avoid slow I/O. The price we pay for quick retrieval and writes is normalization. While normalization is a goal, it does not scale very well. As a result, when designing tables using NoSQL, you should flip this concept on its head entirely. The more unstructured or denormalized the table, typically, the better. That is because we want to combine multiple tables into a single table even at the cost of duplicating records, or repeating rows in some cases. Obviously, we want to avoid this if it is possible and do this blindly. This is where the single table access pattern can help us understand the most valuable information to retrieve.
Example
With the theory out of the way, let's take a look at a working example of taking a normalized set of relational tables and applying the concept of Single Table access. Let's take a simple use case scenario, a contact list. As shown below, each contact can have multiple phone numbers and multiple addresses.

Currently, on the Contact table, we have foreign Key (FK) which refers to a list of Addresses. How would we model this relationship using NoSQL?
The answer is...you guessed it...denormalization. We would take each record in the child table and combine it with the parent table. Thus, producing three records in this case.
Denormalized Data
With the denormalization out of the way, we now have a working table like this:
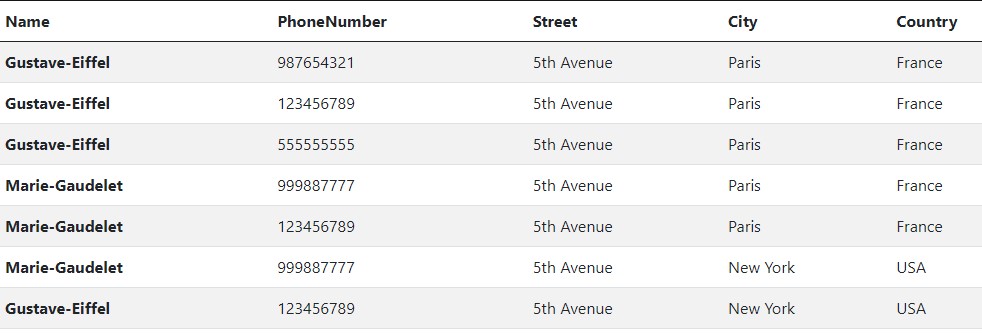
Since we don't have a foreign relationship, we can now drop the foreign keys. What we end up with at this point is a record repeated three times. The data is at a point in time where we can start to think about the different ways we would want to retrieve it.
The Importance of Designing Access Patterns
The most important part of this process is to understand and identify the correct way to retrieve your data. Making this mistake is a costly one because typically NoSQL tables have extremely high amounts of data. Having to change your access pattern means, you need to re-index all of it. Alternatively, you could create a different way of querying your data but particularly with DynamoDB, every index added to a table, becomes a replica of that data. This means if you have two indexes, you are essentially using two copies of your data. Adding more GSI's does not always guarantee a fix because, at this time, you can only add up to 5 GSIs in DynamoDB. Because of these limitations, you should consider carefully and understand how that data is going to be retrieved. Let's review our example in more detail.
Identifying Access Patterns
While in this scenario it may be obvious what choices should be made, be sure to take the time to apply this exercise, the choices may not be so obvious when it comes to query selection. Using the questioning method, we ask ourselves what data is most likely to be needed. This could come from requirements and acceptance criteria or our judgment.
Question's to ask:
- How can I retrieve information for a contact?
- How can I deal with contacts having the same name?
- How can I deal with contacts that have a name change?
- By Phone Number
- By Email Address
- By Address
Defining Our Primary and Sorting Key
For the sake of this example, we'll discuss the process of creating the primary and sorting key from the information listed above.
Primary Key
Our first step is to identify the primary key. Looking at the above, we might be tempted to use the email address as our primary key and while that's possible, a user may not register an email address for fear of being sent unwanted emails. Also, for social media integration support, we may not have this information necessarily available. Let's assume for the solution, these two statements hold true. Our system is primarily focused on capturing information available without the need for an email address.An alternative approach would be using the user's first and last name as the primary key in this context. This would identify the individuals that share a common name. It is also most likely that from a data-entry standpoint, a client would enter this information first before moving on to any other.
For Gustave Eiffel, we could use the following format as a potential option.
PK: Gustave-Eiffel
Sorting Key
For our sorting key, we want to take advantage of a composition key. A composition key is one where bits and pieces of the key are composed of different values. This will come in handy when we are using retrieval access depending on the information available or defined. Another important aspect of defining your sk is understanding the precedence of each part of the information available.Locating A User by Address
We have the following data:- street
- city
- country
SK: streetTo combine several parts of information, we can make use of a delimiter to denote the different components of the key we want to retrieve based on what information is available. We decide to use the '#' symbol which has become a common practice.
SK: street#
With these eliminated from our list, we now have the following attributes to consider:
- city
- country
SK: street#city#countryThat said, how do we deal with whitespaces or special characters?
We could perform a minor transform to use snake-case to remove whitespaces and replace them with hyphens and store special characters in ASCII.
Here is an example:
- Name: Gustave Eiffel
- Street Address: 5th Avenue
- City: Paris
- Country: France
PK: Gustave-Eiffel
SK: 5th-Avenue#Paris#France
What does this accomplish though? Why would this be useful?Well, first we can make control a query through the SK components to widen or narrow a query result set. If we wanted to know all the individuals with a name of Gustave we would simply query like this:
PK: Gustave-Eiffel
SK: 5th-Avenue
This would show all accounts that have a name with Gustave Eiffel that live on 5th Avenue. That said, this would also match individuals who live in other 5th Avenues around the world such as New York. Notice, we are using the same PK and SK here to retrieve different results based on the data we supply to the query. We accomplish this by using the SK with the PK to identify records we're interested in returning.If we wanted to narrow the scope down a bit further, we can include the city as part of the search:
PK: Gustave-Eiffel
SK: 5th-Avenue#Paris
We can certainly narrow this query even further by providing the country:
PK: Gustave-Eiffel
SK: 5th-Avenue#Paris#France
This query is the most specific because unlike the previous permutations, we are specifying the country which reduces the possibility of more than one match.Fun fact, there are currently 48 cities around the world that share the name Paris so having more than one result can happen if we don't specify a country.
Let's review the queries we posed at the beginning of this section. Question's to ask:
- How can I retrieve information for a contact?
- How can I deal with contacts having the same username?
- How can I deal with contacts that have changed names?
Answer 2: Since we are also using the sorting key in combination with the PK, we can use the contacts name and address to distinguish between common names between different users.
Answer 3: In cases where a name change occurs, we need to figure out how to still retrieve a record. The contact could simply update their last name on the front-end system. On the back-end, we would still query thier maiden name and perform an update on the sorting key. This would create a new record in the database but retain the data associated with the record. This could be accomplished through a preferences user interface where the user can perform actions such as name changes and update addresses since these things tend to change over time.
With all of this design out of the way, we are almost ready to create our table. Remember, we haven't implemented anything and we still want to think through a few more scenarios before doing so.
Here is our potential table so far:
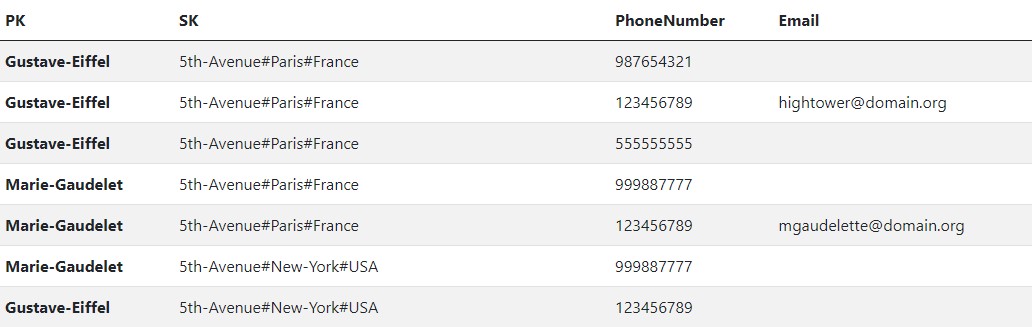
Identifying More Access Patterns
Another popular search method would be to use the phone number associated with the contact. Ultimately, it comes down to the application requirements that define the best way to identify access patterns. If we're building a Call Center application then you could argue we don't need the previous access pattern at all. If, however, we have a situation where the user is unable to locate a previous address in the system, we still need a way to retrieve the users information as an alternative.
We have the decision to make, we can either add a GSI or store the information differently. Let's use the flexibility of the PK and SK to accomplish this without introducing a new GSI.
To search by a user, we could use the phone number as the primary key in this context.
PK: 123456789
This would automatically narrow our search results to a very specific set of individuals.For our SK, we can leverage the contact's name and address.
SK: name#street#city#country
Here is the current state of our design and the information associated with it.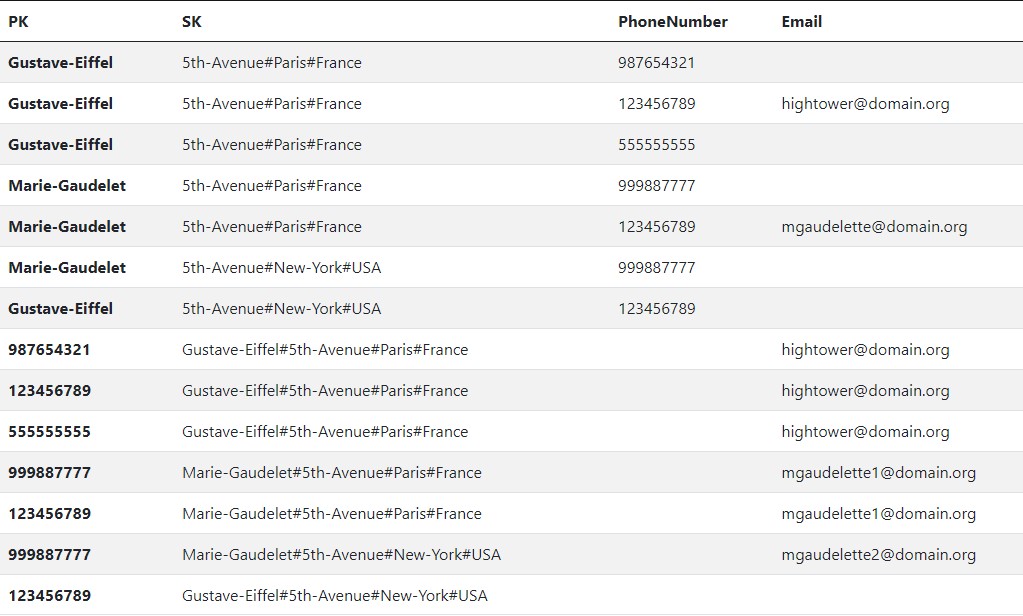
Unstructured Data
If you've been keeping an eye on the denormalization process, you'll notice something else, our data is now unstructured vs a structured record set. This is another fundamental difference between the two types of databases. In RDMS, we are guaranteed to have attributes defined on a record with constraints whereas in NoSQL, if it is not part of the PK or Sk, nothing is guaranteed.
This does come with some advantages because with the naming conventions we've applied to our above table, as the name implies, we can persist different types of entities as a result of the very nature of unstructured data so long that it satisfies the PK and SK requirement.
Another important note, because we've defined our PK and SK as generic types, notice we did not define the PK as "Name", we can store different types of entities within the same table. We can even use different retrieval access patterns while still leveraging the same table. Again, we review the original questions we posed:
- How can I retrieve information for a contact?
- How can I deal with contact's having the same username?
- How can I deal with contact's that have changed names?
Answer 2: Since we are also using the sorting key in combination with the PK, we can use the contacts name and address to distinguish between common names between different users but this case is highly unlikely.
Answer 3: We solve this challenge by providing an interface that allows a user to update the SK. In other words, we have a UI screen where a user can update their preferences. From the back-end, we perform an update on the record and capture the information associated with the user on the new information.
Up to this point, we've only considered storing a single entity but what happens when we store multiple types of entities?
Another question, what happens if we have similar data where it isn't so straightforward to distinguish between similar entities?
For example, we now have two types of contacts that contain similar data. How can we distinguish between them?
Well, like the very nature of storing data, we need a way to identify a type of record. A common practice is to store an entityType (string) value which represents the record type. By doing this makes it easier for consuming application to query data properly using filtering on the specific type of entity being requested.
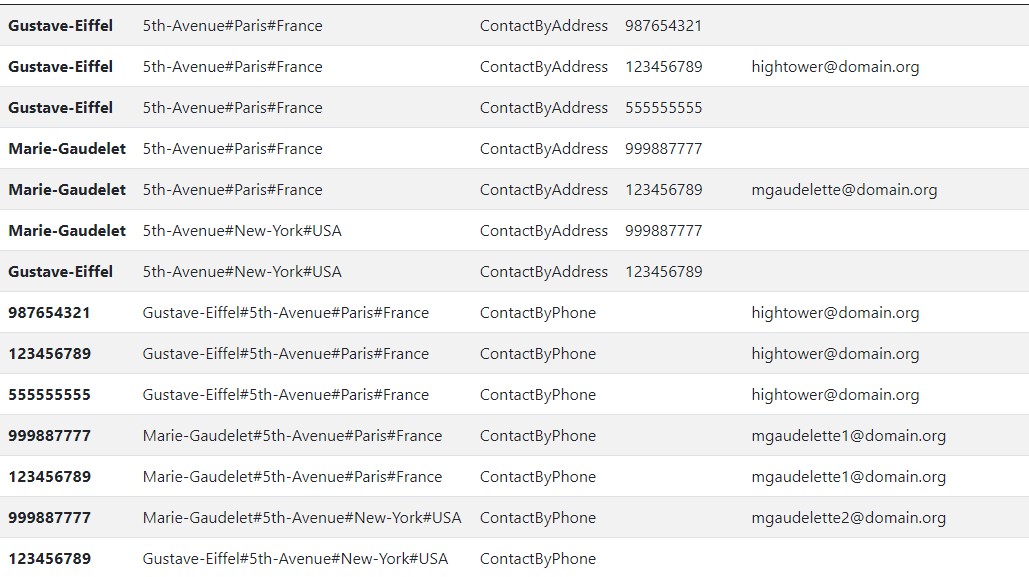
Supporting Books and Other Entities
Because we've defined our Primary and Sorting Keys as generic types, we can reuse these columns to support storing more than one particular entity. We can repeat the same process for storing books as an example.
Doing this, we can define our Primary Key with the title of the book.
PK: Moby-Dick
Next, using the questioning method, we can identify the most valuable information from a book. Typically, the author or publishing company would rank highest, followed by the edition, copy format and language.We end up with this:
SK: author#edition#format#language
Let's take a look at our design with these different entities co-existing in the same table.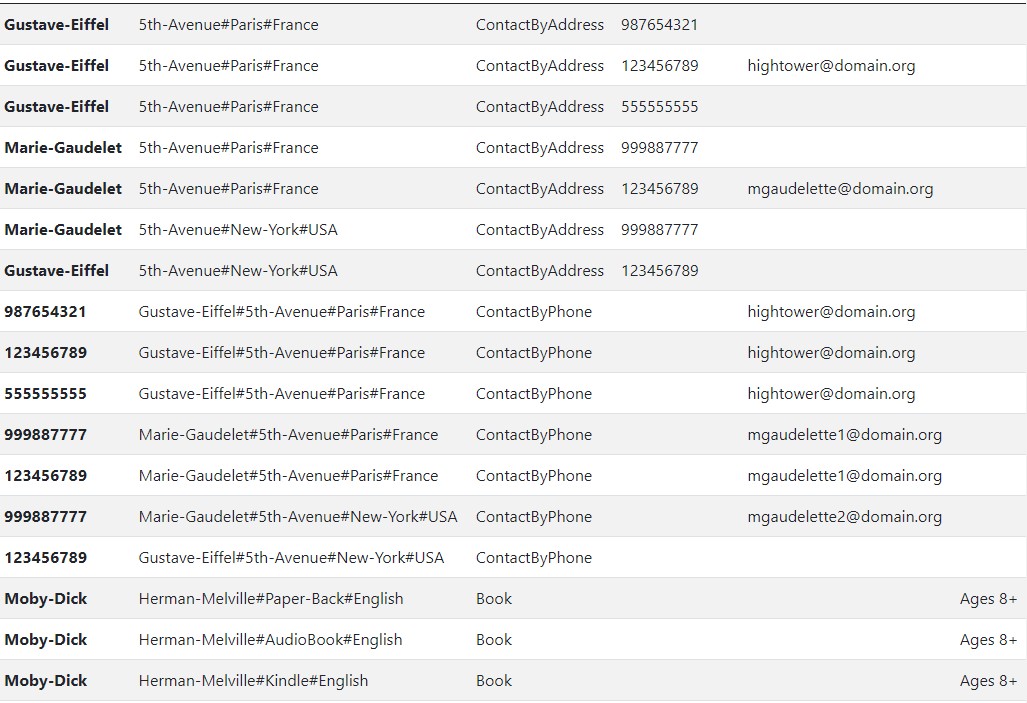
A few things to check out, each entity will make use of the metadata that applies to it. You can verify that book-type records do not always make use of an email attribute. For our contacts by phone object, it never uses the age group, although it has the flexibility to do so.
The key point here is that we did not change the primary key nor did we need to change the sorting key columns. Rather, we simply construct a key that fits the needs of our access pattern for a given entity.
Following the process, we ended up with these entity sk and pk mappings. We can now support over 10 queries without changing our table.
It is possible to query:
- Books by author
- Books by publishing type
- Books by language
- Books by page length
- Contacts by name and phone number
- Contacts by street
- Contacts by city
- Contacts by country
Conclusion
Hopefully, you can see how powerful this approach is and how quickly you can scale out a single table using this method. When volumes of data become a problem and you need fast access, this is a great way to have an excellent and performant table that can handle changes in a robust manner.
Now that we've thrown several variations of this, we're ready for implementation.
Ultimately, theneeds of your application should dictate the "right" way to access your data.